Key Findings
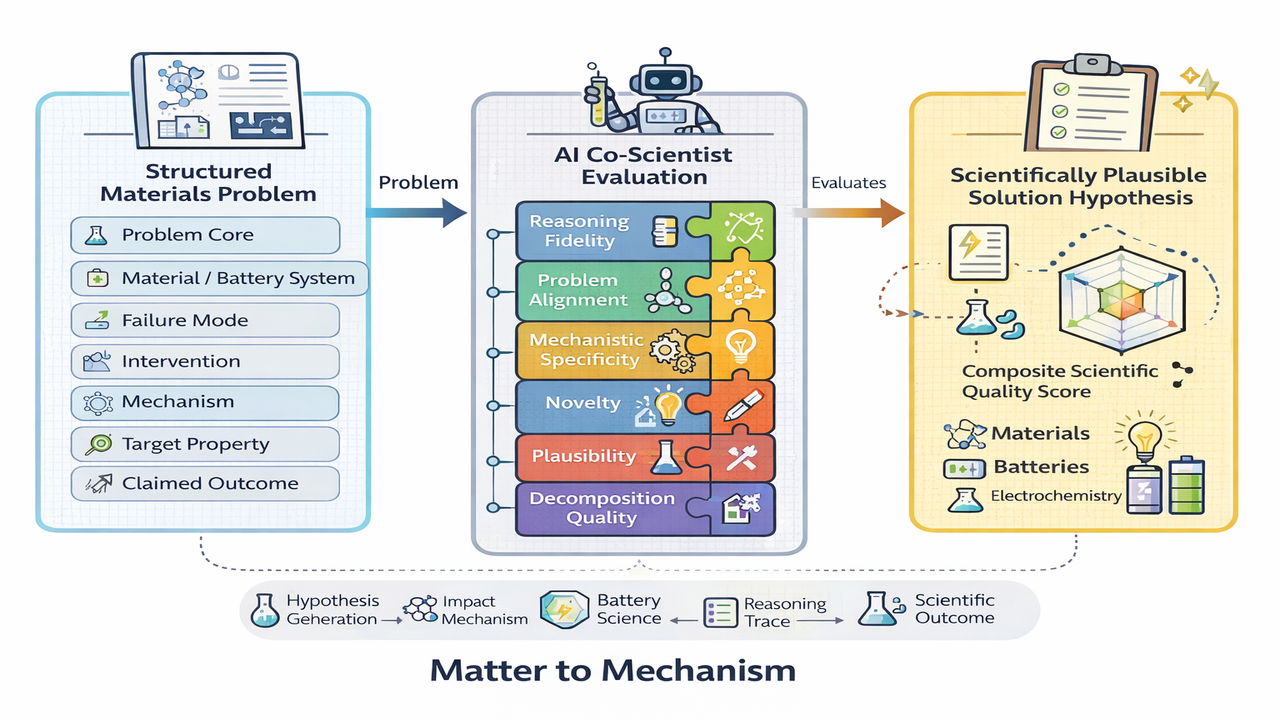
Google Research has introduced “Matter to Mechanism,” an innovative benchmark designed to objectively evaluate the scientific reasoning capabilities of AI co-scientists. This benchmark is specifically designed to measure how accurately AI can generate reliable, mechanism-based solution hypotheses from specific scientific and technical problems. It includes 2,645 instances derived from scientific papers, with a particular focus on battery materials research. By providing new metrics such as inference fidelity, problem alignment, mechanistic specificity, novelty, and plausibility for AI systems, it holds the potential to significantly enhance the reliability and efficiency of AI-powered scientific discovery.
Technical / Clinical Details
- Matter to Mechanism Benchmark: This benchmark takes a scientific problem as input (e.g., the cause of performance degradation in a specific battery material) and prompts the AI to generate a mechanism-based hypothesis as output (e.g., internal short-circuit due to lithium dendrite formation). The quality of the generated hypothesis is then numerically assessed based on expert evaluation criteria.
- Dataset from Scientific Literature: The benchmark dataset comprises 2,645 diverse pairs of real-world scientific problems and their mechanistic solutions, extracted from scientific papers on battery materials research. This allows for evaluation of how effectively AI models function within actual research contexts.
- New Evaluation Metrics: While traditional AI model evaluations often prioritize simple prediction accuracy, Matter to Mechanism introduces more sophisticated scientific judgment metrics: “inference fidelity” (whether the hypothesis contradicts input information), “problem alignment” (whether the hypothesis is relevant to the problem), “mechanistic specificity” (whether the hypothesis describes a concrete mechanism), “novelty” (whether it offers insights beyond existing knowledge), and “plausibility” (whether the hypothesis is scientifically acceptable).
- Enhancing AI Co-Scientist Capabilities: This benchmark allows AI models to be objectively measured and improved not merely as data processing tools, but as “co-scientists” capable of generating scientific insights and assisting researchers.
Background & Context
In recent years, AI technologies, including Large Language Models (LLMs), have begun to be applied to various stages of scientific research, such as analyzing scientific literature, generating hypotheses, and formulating experimental plans. However, standardized methods for objectively evaluating the quality and reliability of AI-generated scientific ‘reasoning’ have not yet been established. Particularly in complex fields like battery material development, understanding the underlying mechanisms is crucial, and AI is required to be an interpretable and reliable scientific partner rather than a ‘black box.’ Google Research’s initiative addresses this critical gap.
Strategic Significance & Outlook
The introduction of the Matter to Mechanism benchmark will accelerate the development of AI co-scientists and dramatically improve the speed and efficiency of discovery in battery materials research. As AI becomes capable of generating more reliable hypotheses, researchers can more quickly identify promising research directions and reduce the risk of experimental failures. In the future, this benchmark is expected to be applied to evaluating AI’s reasoning capabilities in other materials science domains and other scientific fields. This will promote the credibility and adoption of AI-driven science, increasing its potential to solve complex challenges facing humanity.








Comments